- Grimport Language Documentation
- Installation of Grimport & Other Software
- Variables & Syntax
- Control Structures
- Extract data from a page
- Export Filtered Data
- Programming with Grimport Script Editor
- Crawler and Logs
- GRS, GRC & GRL
- Folder Organization
- Launch Options
- Cache
- Mistakes & Errors
- Connected services
- To Go Further
Extract data from a page
In this part, we will see how to extract data with CSS selectors and regular expressions. To do so, we will explain what a CSS selector and a regular expression are and how they work.
Scraping data
Scraping data with CSS selectors
Each element of a web page is registered by one or more unique CSS selectors. You can use these CSS selectors to extract content from the HTML elements on a web page.
Selectors are part of the CSS rule set and select HTML elements based on their ID, class, type, attribute or pseudo-classes.
Here are some basic CSS selectors:
Selector |
Example |
Example description |
|---|---|---|
| #id | #firstname | Selects the element with id="firstname" |
| .class | .intro | Selects all elements with class="intro" |
| element.class | p.intro | Selects all <p> elements with class="intro" |
| * | * | Selects all elements |
| element | p | Selects all <p> elements |
| element, element | div, p | Selects all <div> elements and all <p> elements |
You can go to this page for more CSS selectors.
Tutorial
Now we will learn how to use CSS selectors to extract data from an HTML page.
To find a web page's CSS selectors, you need to do the following:
Open Chrome or Firefox, right click on the targeted element and click on Inspect. Go to the highlighted line and right click, you can go to Copy > CSS Selector and see what the browser has guessed.
You can then try it in the Test tab of Grimport Script Editor to confirm you've chosen the right CSS selector.
For example, we will use this web page: Test Page
#id css selector
An id selector is used to select a single element or all elements with the selected id.
To retrieve an element with an id, type a hash character (#) followed by the element id.
CLICK TO ZOOM
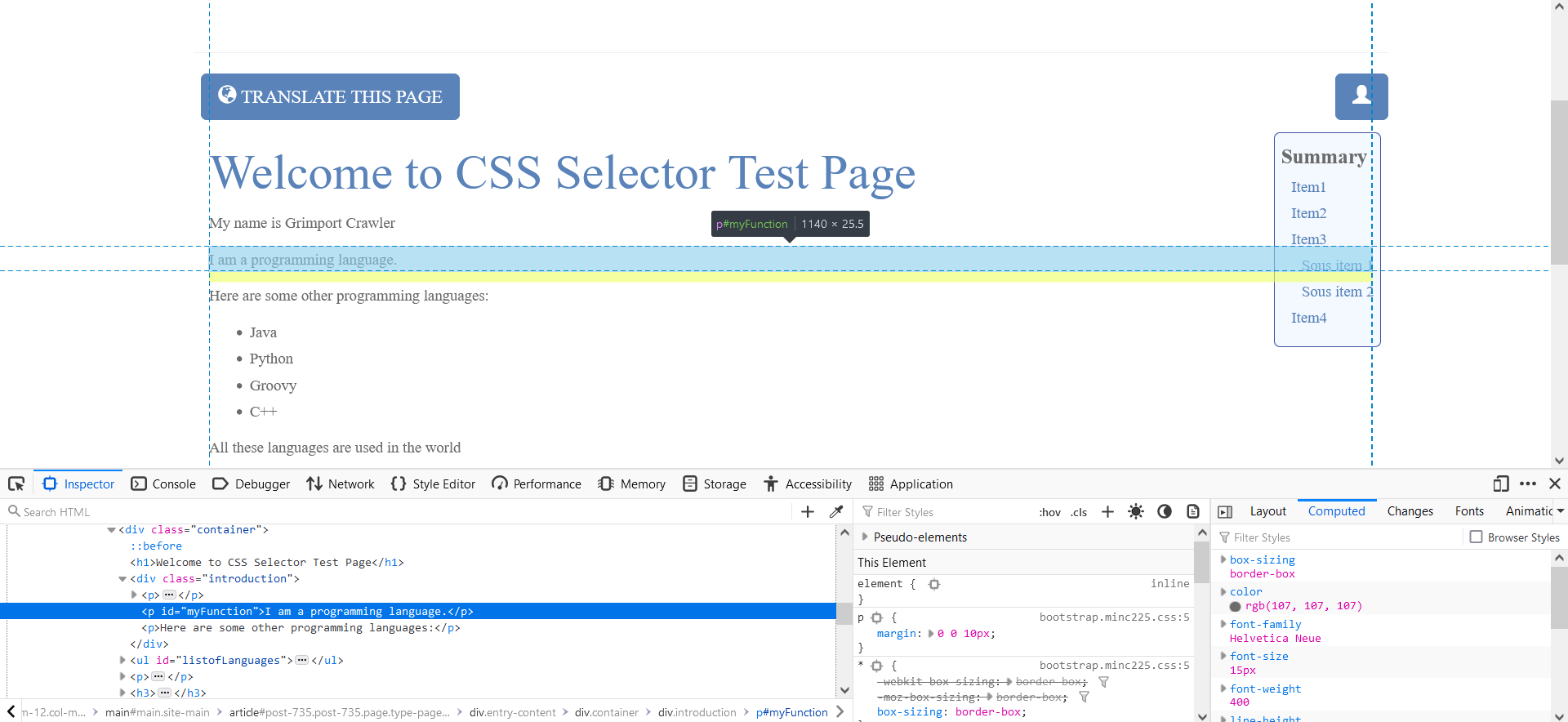
“I am a programming language” is extracted using the #myFunction selector.
.class css selector
A class unlike an id can be used to identify multiple elements.
The class selector extracts all elements with a specific class attribute. To select elements with a class, write a dot character (.) followed by the class name.
CLICK TO ZOOM
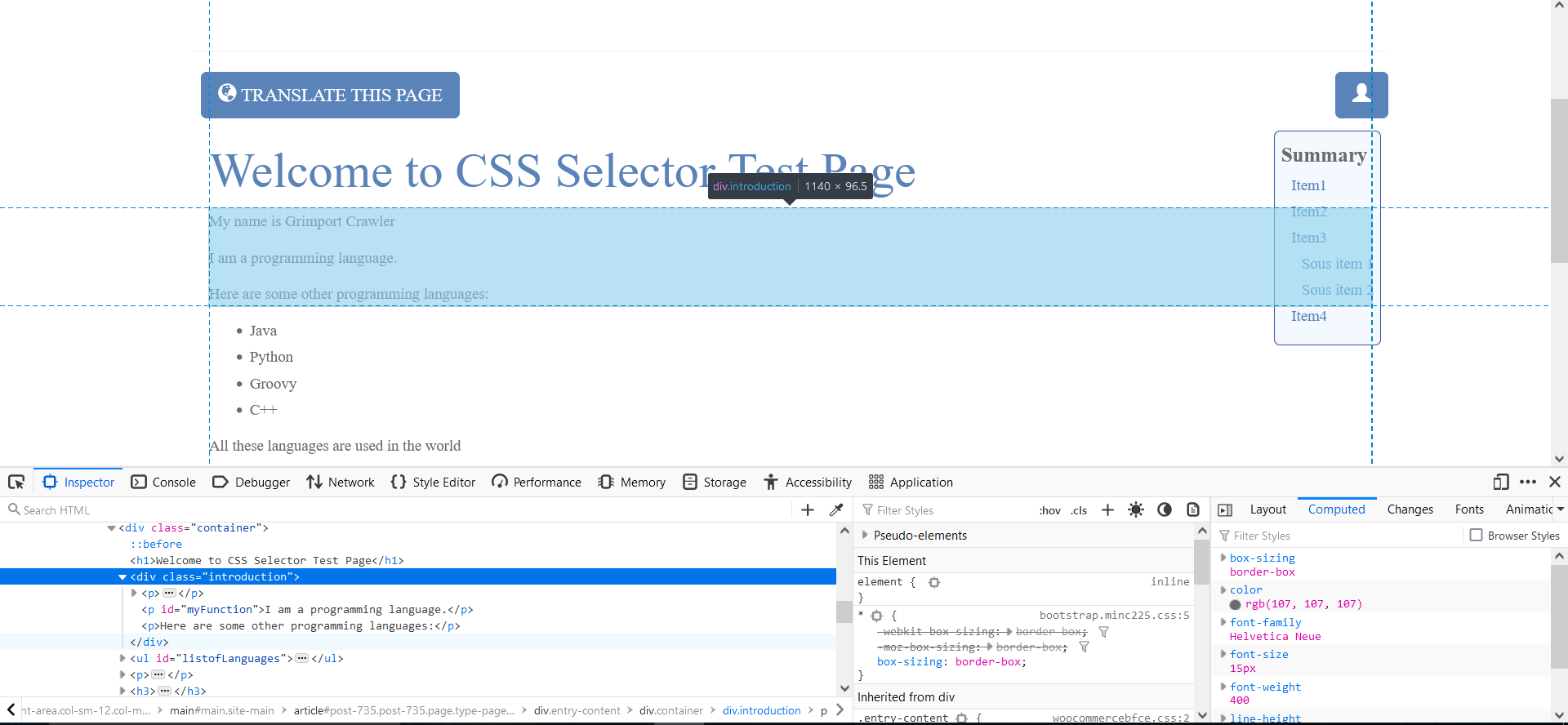
Here, the .introduction class is used to extract all the selected elements in the image above.
Now that you have seen how these css selectors work, you can practice using other selectors.
Css selectors with GRIMPORT
We will now see how we can implement them in a Grimport script.
In order to extract specific information from a CSS selector, we use the select() function:
cleanSelect ( string cssSelector , string _code , string _selection )Parameters beginning with an underscore (_) are optional.
The first parameter is the CSS selector parameter which must be enclosed in quotes (because it is a string). The other parameters are optional.
The second argument, allows you to indicate the code in which the search for the CSS selector should be done. If this parameter is null, the function will use the whole source code of the page being crawled (if you are in a FORPAGE script).
The third argument indicates what you want to extract from the element. It is not enough to indicate an element of the source code, you must also say what you want to take from this element, do you want the HTML with the tag of the element (outerHTML), or the HTML inside the tag (innerHTML), the text of the element without the tags (text) or an attribute of the element like the src property of an img tag (indicate the name of the attribute, e.g.: "src")
If there are elements corresponding to this CSS selector, select() returns the contents of the first selector found.
HTML:
<ul id="listofLanguages">
<li>Java </li>
<li>Python </li>
<li>Groovy </li>
<li>C++ </li>
</ul>
Grimport:
firstLanguage = select("#listofLanguages li")
console(firstLanguage) // -> "Java"
allLanguages = select("#listofLanguages", null, "text")
console(allLanguages)
/* -> "Java
Python
Groovy
C++"*/There is a very useful function that can clean the data and extract it at the same time: cleanSelect. The function is the same as select, with a 4th argument which is the data cleaning mode.
All functions select, selectAll, regex, regexAll, have equivalents that include data cleaning. You just have to capitalize the first letter and then add clean in front.
If you want to extract all elements matching the selector, you can use selectAll() to find them all.
Example (with cleanSelectAll !) :
HTML:
<ul id="listofLanguages">
<li>Java </li>
<li>Python </li>
<li>Groovy </li>
<li>C++ </li>
</ul>
Grimport:
language = cleanSelectAll("#listofLanguages")
console(language) // -> ["Java", "Python", "Groovy", "C++"]Scraping data with regular expressions
Sometimes we can't extract the elements we want to extract with CSS selectors because the web page lacks the identifier or class, or because it is not HTML (we want Javascript for example). We will then use regular expressions, also called regex.
The use of regular expressions has the advantage of allowing the expression to adapt flexibly to any type of string.
It is a very powerful tool that uses a specific search pattern.
Here is a page that will allow you to know the basics of regular expressions: Regular expressions Basic topics
Tutorial
Before starting this tutorial, I advise you to know the basics of regular expressions.
In this example, we will use the following page: Test Page
Some elements of this page will be more difficult than others to extract, so we will use regular expressions.
You can also test your regular expressions on Grimport Script Editor in the Test tab.
Here we want to extract the title of this page: "Welcome to CSS Selector Test Page".
CLICK TO ZOOM
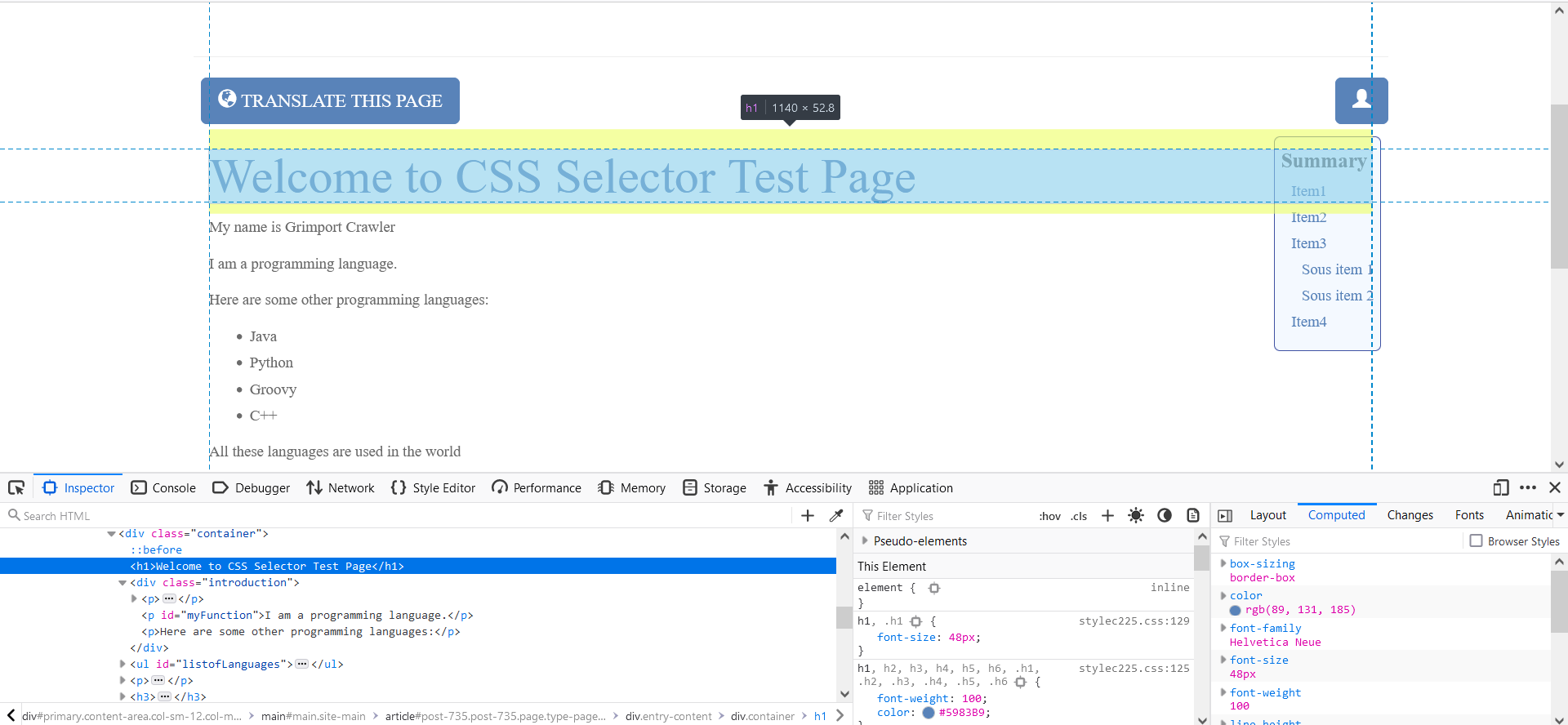
The part of the code that interests us is:
<h1>Welcome to CSS Selector Test Page</h1>
/(?si)<h1>\s*([^<>]*)<\/h1>/
It sounds scary, but it's actually very simple:
- First, the special flag declaration (?si) tells the regex that the . include the caracter newline (s) (by default it is not the case), and we ignore case differences (i).
- Then there is the literal <h1> which means that what we want to extract starts with the string <h1>.
- \s* signals that there can be any amount of white space.
- What we want to extract is in the parantheses. This is called an extraction mask.
- [^<>]* means that we want all the characters that exist except for < and >.
- Finally, <\/h1> indicates that we want to stop here. There is a backslash before the /h1 because it is an escape sequence. Indeed, the / character is used to delimit a regular expression, a bit like the " character which delimits a string.
title = regex(/(?si)<h1>\s*([^<>]*)<\/h1>/) console(title) // -> "Welcome to CSS Selector Test Page"
Sometimes it makes sense to be a little more specific than <h1> at the beginning of the regex when there are multiple <h1>.
For example, in the page code, there are multiple <h2>, however we only want to extract one: "Java Programming Language"
CLICK TO ZOOM
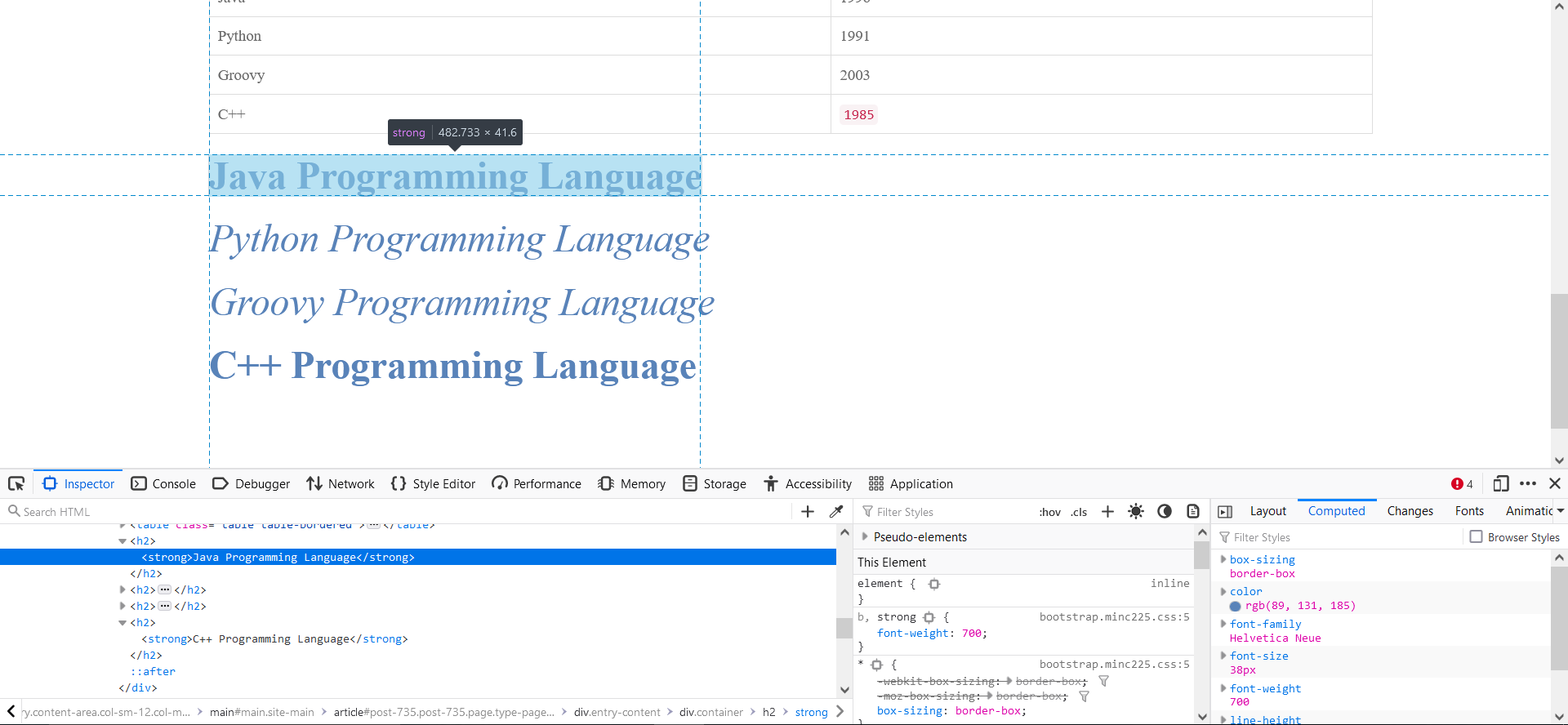
It will not be enough to write :
(?si)<h2>\s*([^<>]*)<\/h2>
It will then be necessary to write :
(?si)<h2><strong>([^<>]*)<\/strong><\/h2>Moreover here, several <h2> subtitles are in strong, that is to say that this code will correspond to several subtitles. We will see in the part below how to avoid this problem.
Regular expressions with GRIMPORT
We will now see how this is done with Grimport.
Here, we use the cleanRegex() function:
cleanRegex ( string regex , string _code , string _postProcessing , int _numberOfMask )cleanRegex() returns the mask of the first regex found:
language = cleanRegex(/(?si)<h2><strong>([^<>]*)<\/strong><\/h2>/)
console(language) // -> Java Programming LanguageYou can then use cleanRegexAll(), which returns the mask of a regex for all matching instances:
language = cleanRegexAll(/(?si)<h2><strong>([^<>]*)<\/strong><\/h2>/)
console(language) // ->[Java Programming Language, C++ Programming Language]You can then use the list extraction functions on what cleanSelectAll returns to take for example the second element of the array with the get() function:
language = get(cleanRegexAll(/(?si)<h2><strong>([^<>]*)<\/strong><\/h2>/),1)
console(language) // -> C++ Programming LanguageYou can also extract all h2 by changing your regular expression:
h2 = cleanRegexAll(/(?si)<h2><[^<>]*>([^<>]*)<\/h2>/)
console(h2) // -> [Java Programming Language, Python Programming Language, Groovy Programming Language, C++ Programming Language]h2 = regex(/(?si)<((h2)|(h1))><[^<>]*>([^<>]*)<\/((h2)|(h1))>/, null, 4)
console(h2) // -> "Welcome to CSS Selector Test Page"
Data cleaning
One of the important tasks in any web application is proper sanitization and standardization of data. Any data stored in a database should be in a standardized format, especially data that comes from external sources.
There are several functions that allow the cleaning of data in order to standardize it. Here are the main ones:
- standardizeText() allows the correction of many problems like encoding errors, it converts HTML codes like é into "é" character and it replaces some apostrophes like ‘ with the Unicode code standard apostrophe '.
- stripTags() allows the removal of all HTML tags from a code.
- number() allows the extraction of a number from an HTML code.
- htmlToPrice() allows the extraction of a price from a potentially "dirty" code.
In Grimport, we will favor using functions starting with "clean" like cleanSelect() or cleanRegex() over select() and regex() because they are made of an additional argument _postProcessing which is a cleaning function.
By default, this argument will correspond to standardizeTest + stripTags.
Here is how the _postProcessing argument is constructed:
- null or nothing = stripTags + standardizeText
- "description" or "d" = standardizeText
- "price" or "p" = htmlToPrice
- "number", "decimal", "float" or "n" = number with decimal
- "integer" or "i" = numeric integer
- "none" or "-" or "." or "0" = nothing
For example, if you want to extract a price with the select() function, it is better to write:
myPrice= cleanSelect("#myPrice", null, null , "price")
Rather than:
myPrice = htmlToPrice(select("#rrp-price"))
Now that we've seen how to extract data with CSS selectors and regular expressions and you've seen how to clean up the data, I'd like to show you a short video example that will allow you to extract information from an online product on this page:
Next ❯ ❮ Previous